llm-mem
Note of llm training memory requirements.
Who lives inside of the memory during the llm training?
- Model State
- model parameters
- gradients
- optimizer states
- Residual State
- activations
- temporary buffers
- unusable memory fragments
Before deepspeed how to scale?
| Feature | Data Parallelism (DP) | Tensor Parallelism (TP) | Pipeline Parallelism (PP) |
|---|---|---|---|
| Definition | Distributing data across multiple devices | Distributing different parts (tensors) of the model across multiple devices | Dividing the model into stages and running them in sequence on different devices |
| Use Case | Large datasets | Very large models that cannot fit into a single device’s memory | Extremely large models that benefit from being split into sequential stages |
| How it works | Each device gets a different subset of the data and trains a copy of the model | Different tensors or parts of tensors are processed on different devices | The model is split into stages, with each stage processed on different devices in sequence |
| Communication Overhead | Moderate, synchronization needed after each mini-batch | High, requires communication between devices for forward and backward passes | Moderate, data passed between stages after each mini-batch but less frequent than TP |
| Memory Usage | Efficient, data is divided among devices | Efficient, each device only needs to store part of the model’s tensors | Moderate, memory divided among stages but requires storing intermediate outputs |
| Scalability | Good for many devices | Limited by how well the tensors can be partitioned into smaller segments | Good, but dependent on the balance of computation and communication across stages |
| Implementation Complexity | Simple, widely supported by frameworks | Complex, requires careful tensor partitioning and synchronization | Moderate, requires managing inter-stage communication and load balancing |
| Latency | Low, as all devices process data in parallel | High, as devices need to communicate frequently | Moderate, can be affected by the time taken to pass data between stages |
| Fault Tolerance | High, losing a device only affects that subset of data | Low, losing a device means losing part of the model’s tensors | Moderate, losing a device affects that particular stage of the pipeline |
| Examples | ResNet, VGG | Transformers, BERT with large tensors | GPT-3, T5, and other large transformer models |
3 stages of ZeRO-DP
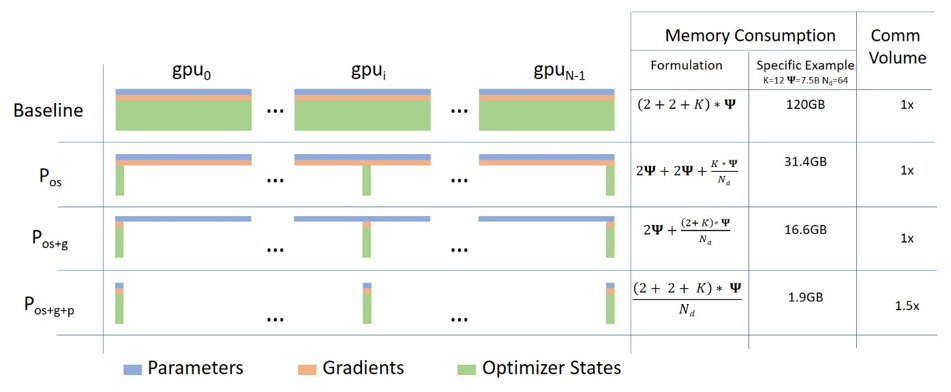
-
Optimizer State Partitioning ($P_{os}$) – 4x memory reduction, same communication volume as data parallelism
-
Add Gradient Partitioning ($P_{os+g}$) – 8x memory reduction, same communication volume as data parallelism
-
Add Parameter Partitioning ($P_{os+g+p}$) – Memory reduction is linear with data parallelism degree $N_d$. For example, splitting across 64 GPUs ($N_d = 64$) will yield a 64x memory reduction. There is a modest 50% increase in communication volume.
How does it work step by step
You want to choose the right config for your training job
