Diart
Note of the paper Diart https://arxiv.org/abs/2109.06483
Context
Speaker diarization is the task of solving “who speaks when”.
multi-stage vs end-to-end
- multi-stage
- voice activity detection to discard non-speech segments
- speaker embedding extraction to get the speaker representation
- clustering to group the speaker embeddings
- end-to-end
- BLSTM (bi-directional LSTM, two processing, one from past to future, one from future to past)
- Self-attention mechanism
The challenge of multi-stage approach is the overlapping speech. The challenge of end-to-end approach is unkown number of speakers and super hard to scale.
Diart
This diart paper is a hybrid approach, which combines the advantages of both multi-stage and end-to-end. It’s more towards the multi-stage approach with over-lapping speech as the first class citizen.
- split the audio into small chuncks, in each chunck, do end-to-end.
- apply global constrained clustering on top of the resulting local speaker.
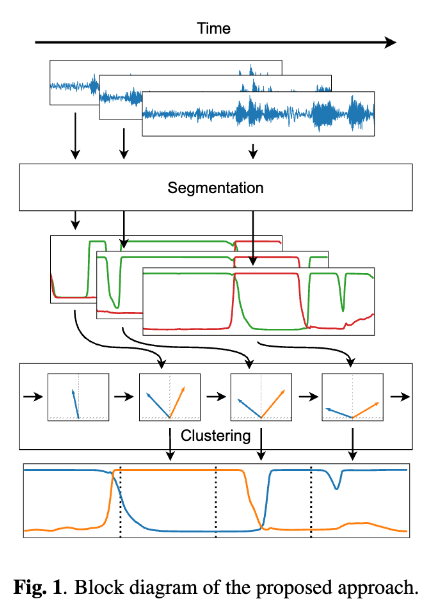
Segmentation
Every few hundred milliseconds, the segmentation module do a fine-grained overlap-aware speaker diarization. it’s a end-to-end model.
Incremental Clustering
The local diarization is then ingested by the incremental clustering module
- TDNN (time delay neural network) is used to extract the speaker embeddings.
- Given the initial content of the rolling buffer, the segmentation and embedding steps are combined to extract one embedding for each speaker in the first 5 seconds of the audio.
- Every time, when the rolling buffer is updated, the incremental clustering module is triggered to update the speaker embeddings and the speaker cluster assignments.
- Detecting the new speakers, have hyper-parameters to control if it’s a return speaker or new speaker.