RLHF-PPO-part2
This blog is the second part of the RLHF-PPO
TRPO
- Trust region policy optimization enforces KL divergence constraint on the policy update
- It’s doing off-policy RL. There are two policies. one is used for collecting trajectories. The othere one is used for optimization.
- Importance smpling is the objective function.
- Want to make sure the policy update is not too big. using the KL-divergence to measure the difference of two distribution.
PPO
-Introduce the clip function make sure the probability ratio between old and new policies are around 1. -It takes the min between the origianl value from TRPO and the clip function.
Goal of the RLHF
- Use iguazio to run the pipeline
- Find some bench mark dataset to make the comparison before and after RLHF
- Genaralize the function into the mlrun function hub
Steps:
- The reward model can be a transformer-based languge model with the last unembedding layer removed and add an additional linear layer to the final transfomer layer.
- State in the RL:
at time t, the state is all the conversation text up to this point, both by the model and the human. Based on its policy, the agent’s action a is to generate the next token. The reward is a value with respect of state and action. this is calculated froma reward function.
- Policy Gradient Methods.
optimize the policy of the agent (mapping fo states to actions). Not learning the value function. Improve the policy using the gradient ascent algorithm. The native policy Gradient Method is using monte carlo sampling with actual return. it has bigger variance issue. So a common strategy is to use advantage function estimates return. It shows how much better it’s to tkae a specific action a at state s, compared to the average quality of actions at that state under the same policy. it’s just the action-value - state-value
-
Generalized Advantage Estimation instead of only 1 step look ahead as temporal difference. we use k-steps TD. So there will be some trade-off between bias and variance. if k is small, high bias, low variance. if k is large, low bias, high variance. To banlance that. GAE defineds a exponential moving average with weights.
- Need two models to train during the PPO training:
- Critic: this is the value function
- Actor: this is the policy function
- Alg (this is the implementation of the huggingface’s trl lib)
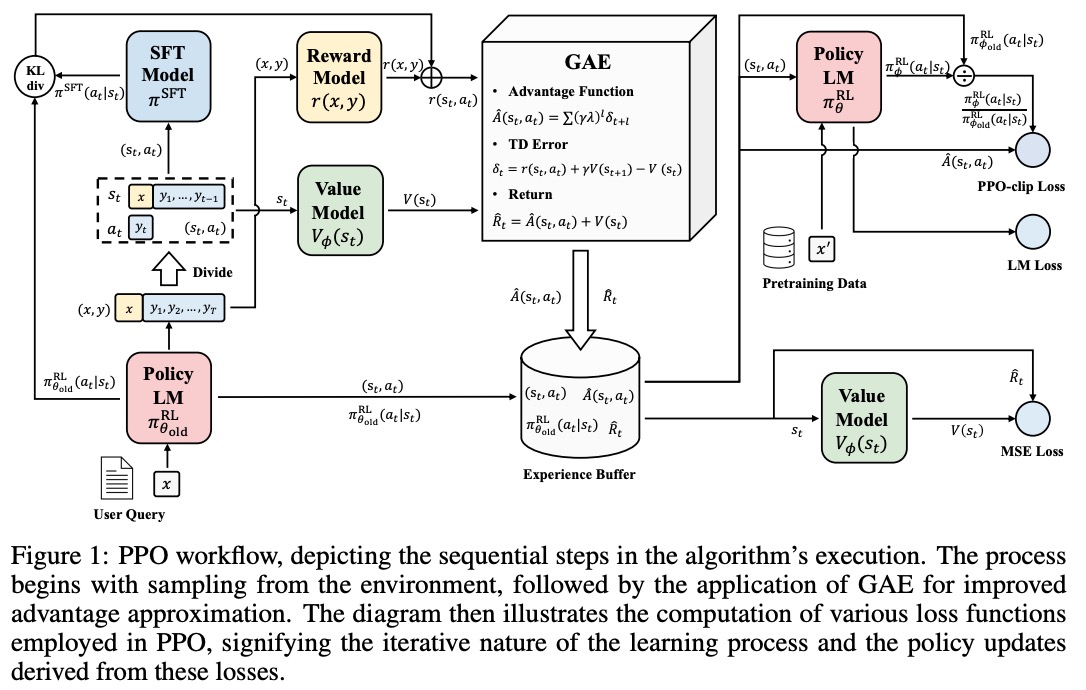
Pain point
- There are 4 models interact with each other during the pipeline training.
- the ref policy model = orignal llm
- the target policy model = target llm (which params will change during the PPO)
- the value function = this is used in the Advantage function
- the reward model = this is used in the Advantage function. (this one is likely to be another llm)
- We only have 4 T4 GPUs to use. it will be super chanllege.